Natural Language Corpora Guidance
What are natural language corpora, and how are they useful?
A natural language corpus is a database of systematically collected words, both written and spoken, which can provide information to be used in the study of numerous natural languages, including Japanese.
Corpora were first constructed around 1960 for use in the study of natural language, but in recent years the use of corpora has expanded beyond the narrow domain of linguistics, and are used in broader areas of research. In addition, they are used outside of academia for corporate research purposes.
The table below summarizes the ways in which corpora are used. Of course, in addition individuals with an interest in Japanese can also make use of corpora to find answers to questions relating to the usage of words.
| Field | Purpose of Use |
|---|---|
| Language Research | General linguistics、Japanese Linguistics、Language study, and other areas of natural language research.Comparative linguistics via the comparison of multiple language corpora. |
| Information Processing | Language modeling for speech recognition、creation of acoustic models.Construction of models for natural language processing.Speech synthesis based on manipulation of phonemic units. |
| Language Education | Development of materials for teaching Japanese as a foreign language.Support for native Japanese language learning. |
| Language Policy | Basic data for studying the table of kanji for common usage.Review data regarding notation in official (government) statements. |
| Lexography | Example lookup. Clarification of relationships between words. |
| Psychology | Design of experiments based on language, stimulus control. |
Creating a Corpus
There are various methods of creating a corpus depending upon the objectives and planned uses of said corpus, but this example will cover the methods used in creating the "Balanced Corpus of Contemporary Written Japanese".
1. Sampling Methods
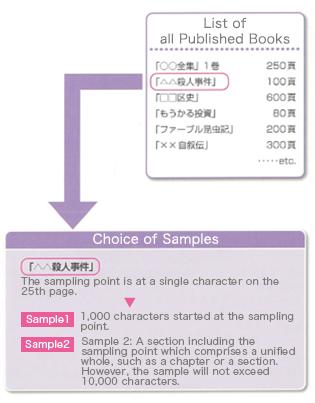
Samples to be used in the corpus are chosen at random.
For example, in the case of samples from books, roughly 30,000 samples were chosen from books published from 1986 to 2005.
When samples are taken, a random character from a certain page is chosen as the sampling point.
In the corpus, there are two types of samples based on the sampling point.
2. Sample Creation
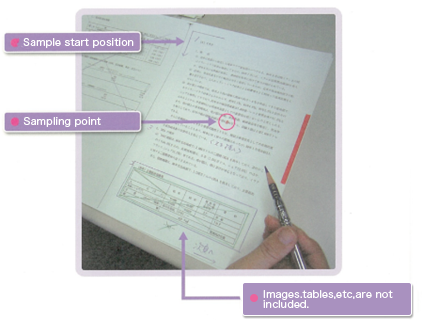
1)Decide on the section to be transcribed in the corpus
Once the sampling point has been chosen, the sample that will actually be used in the corpus is chosen.
2)Complete the copyright process
The copyright process must be completed for each sample. Samples without a license will not be accepted.
3. Digitizing Samples
Samples are then digitized in XML format.

4. Releasing the Data
Each corpus that is constructed will be sequentially made public in the following fashion. However, not all corpora will be made available as described below.
- Free Online Release (Some cases may require a usage contract)
- Paid Online Release (Usage contract required)
- Paid Release of All Data (DVD edition)
The free online release version "Shonagon" can be tried for free.

Corpus Release and Copyright
There is much merit in making corpora widely available. In order to accomplish this when a corpus contains data relating to modern published works which are still under copyright, it is necessary to obtain licenses from the original creator in order for the corpus to be used freely.
In the case of the "Balanced Corpus of Contemporary Written Japanese", over 100 million words of data have been taken from sources such as books, newspapers, and the internet where copyright has not lapsed. Therefore in order for the corpus we have constructed to be used as widely as possible, we have completed the copyright process for all data transcribed in the corpus.
Additional Information for Data Searches (Annotation)
In its simplest form, a corpus of written language is simply text (where samples are arranged as character strings), and can be thought of as a "Text Corpus". Such a corpus can be easily searched for simple and complex conditions using regular expressions.
However, in a simple text corpus, the word "分かち書き" ("word-separation"), for example, could be written in a number of ways in Japanese, such as: "分かち書き", "分ち書き", "わかち書き", "分かちがき, "分ちがき", "わかちがき", or "別ち書き", and in such a case it would be impossible to accurately search a text corpus using only the query "分かち書き". Because of this, there is a need to add further information to the corpus to. This additional mark-up work is called annotation.
The basic annotation process for Japanese "morphological (part of speech annotation) analysis", is as follows.
- Separate the text into "Words".
- Determine the part-of-speech of each word.
- Know the possible variations in representation for words, to decide on the identity of the word.
Aside from morphological analysis, there annotation regarding dependency structure, and predicate argument structure (i.e. subject-object-predicate), and for spoken-language corpora there can also be annotation of speech-to-text transcriptions, phonemes, and intonational information.
When constructing a large-scale corpus, developing an automated annotation system is necessary. For the purposes of morphological analysis, NINJAL and Chiba University have jointly developed technology for the UNIDIC morphological analysis dictionary and a morphological analyzer and have reached a level where practical application is possible.
The Future of Japanese Corpora
In the future, the use of corpora in language research will allow us to lend objective information to the issues of language policy and education, which have thus far been dependent on the opinions of so-called experts.
In terms of basic language research, research that stresses actual patterns of usage over only language structure, research that focuses on the quantitative side of language, and research that does not only look at the underlying systems of language but also at the relationship between language's social context will be facilitated.
In the future, as corpora become more connected to the internet, they will likely expand to billions, or tens of billions of total words. Because it would be virtually impossible for researchers to examine the entirety of the data in such a case, it will become necessary to automatically classify the data using natural language processing and statistical data analysis techniques. As a result, corpora will hopefully contribute to the lessening of barriers between humanities-focused and science or engineering-focused language research.
