まとめて検索『KOTONOHA』マニュアル(検索結果の見かた)
KOTONOHA検索結果の見かた
KOTONOHAの大きな特徴は、指定した検索条件の検索結果(条件に一致した件数)を、グラフを使い視覚的に表示できる点にあります。
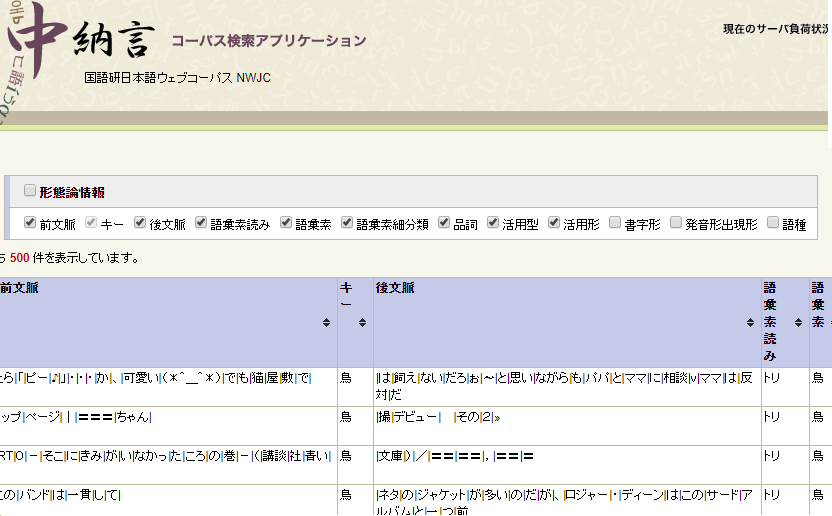
例えば、次のような検索条件を指定します。検索対象は「コーパス毎」です。
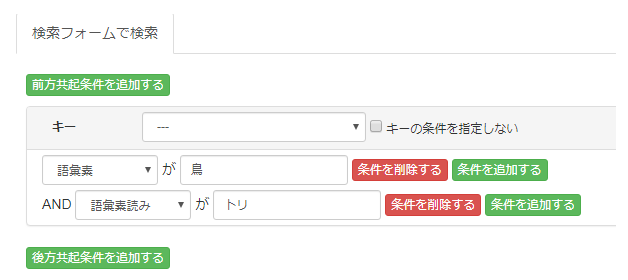
検索結果は以下のように表示されます。
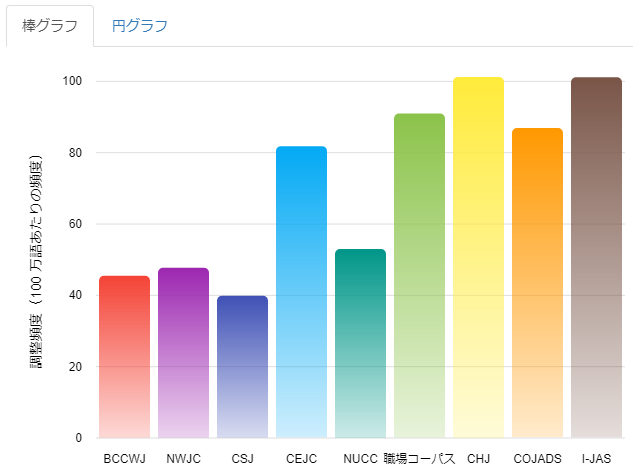
検索対象を「コーパス毎」に指定しているため、
横軸は各コーパス名、縦軸は調整頻度です。
これを見ると、「トリ-鳥」という語彙素が各コーパスにまんべんなく現れていることがわかります。
グラフ上部のタブで、棒グラフと円グラフの切り替えが可能になっています。
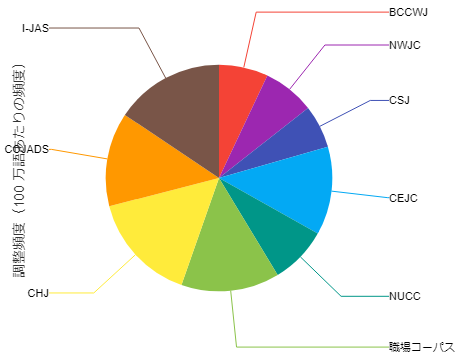
グラフ表示では調整頻度を使って各コーパスを相対的に比較していましたが、
実際の検索結果の件数や、検索したコーパスの規模の統計データもグラフと共に表示されます。
調整頻度のグラフはコーパス全体を俯瞰してみるのには適していますが、
実際の頻度の値を見てみると大きく桁が異なっていることもあるので、グラフはあくまで検索結果を眺める入り口だと思ってください。
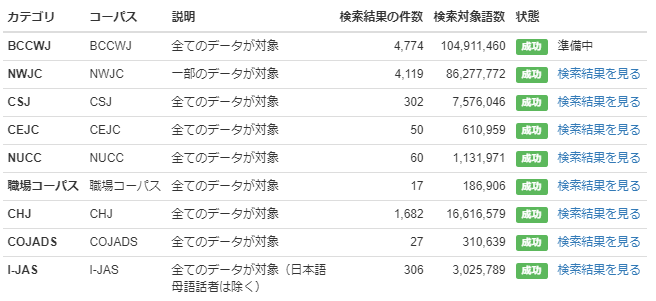
また上表の「検索結果を見る」リンクをクリックすれば中納言へ移動し、前後文脈を含めたキー短単位の詳細な出現を確認できます。
まとめると、KOTONOHAの基本的な使い方は、以下のような流れになります。

ケーススタディ1:書き言葉・話し言葉
上記の例では検索対象を「コーパス毎」にしていましたが、 ここでは「書き言葉・話し言葉」を使ってみます。
例えば、「だ・である調」は、話し言葉よりも書き言葉でよく使われている印象があります。
これをKOTONOHAで検証してみます。
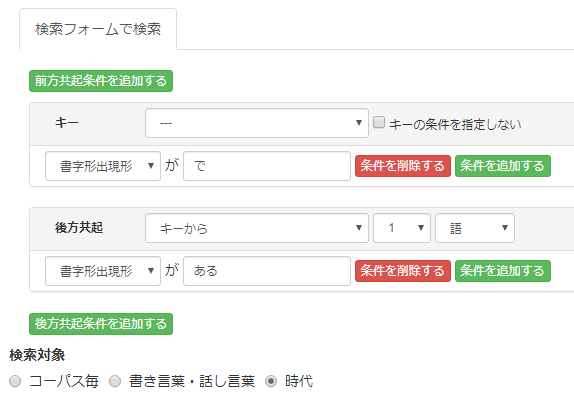
検索条件は次の通り。
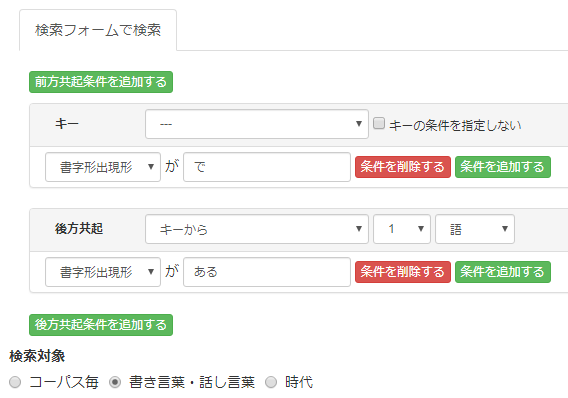
結果は以下のようになりました。
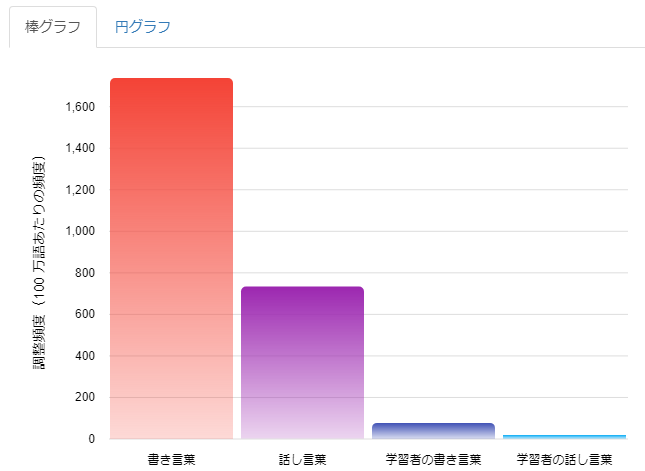
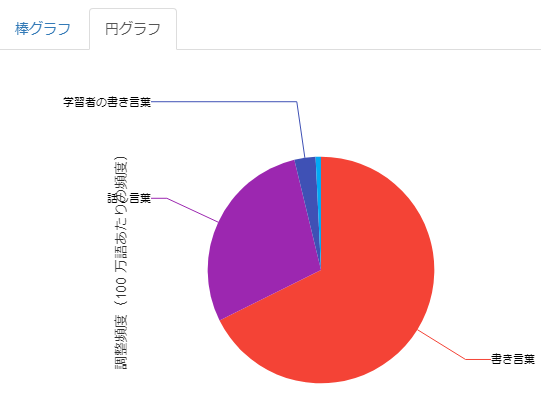
このグラフを見ると「で|ある」は話し言葉よりも書き言葉で多く出現していることが一目でわかりますが、
一方で話し言葉のほうでも思っていたより多く「で|ある」が見つかりました。
そこで、詳細な値を確認してみます。
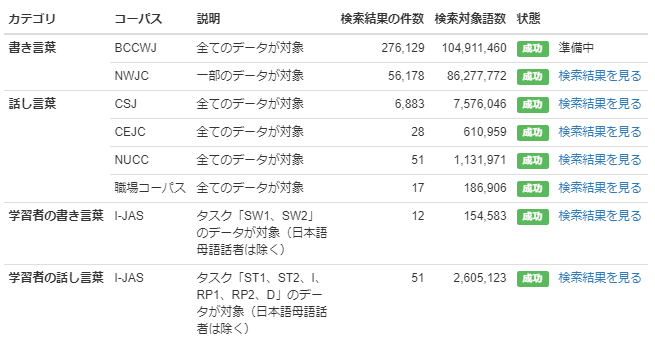
話し言葉の中でもCSJに多く「で|ある」が出現していることがわかりました。
実はCSJには模擬講演や学会講演の発話データが多く含まれていて、
そういった場ではくだけた口調よりも「だ・である調」が使われることが多いのです。
「検索結果を見る」をクリックして中納言で確認してみると、やはり模擬講演や学会講演での出現でした。
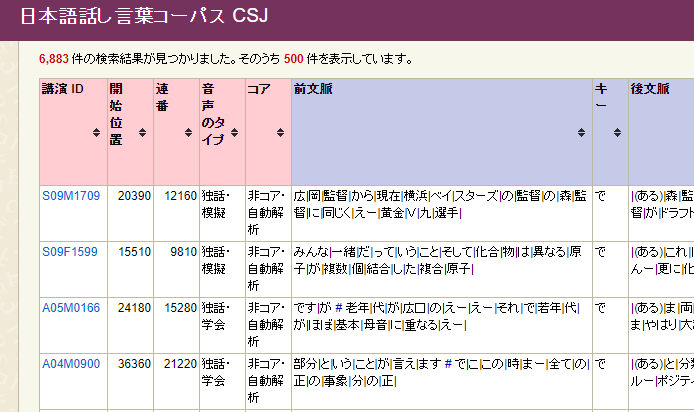
検索対象のカスタマイズ機能「検索対象を設定する」を用いれば、話し言葉カテゴリからCSJのみを取り除いた結果を見ることもできます。
ただし少し複雑な使い方になるため、詳細は応用編:検索対象を設定するで別途解説します。
ケーススタディ2:歴史
ケーススタディ1で扱った「だ・である調」は、歴史的にみると明治時代の言文一致の中で普及してきました。
そこで今度は検索対象を
「時代」に変えて、「で|ある」を検索してみます。
検索条件はケーススタディ1と同じです。ただし検索対象が「時代」に変更されています。
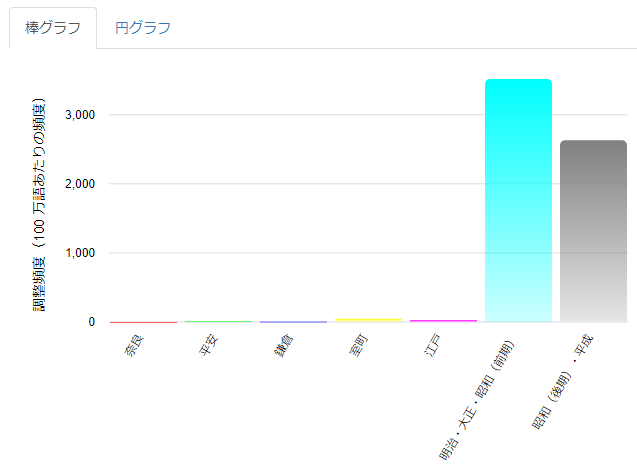
確かに明治・大正・昭和(前期)からグラフが一気に伸びあがっています。
検索結果の件数を見てもその伸び方は明らかです。
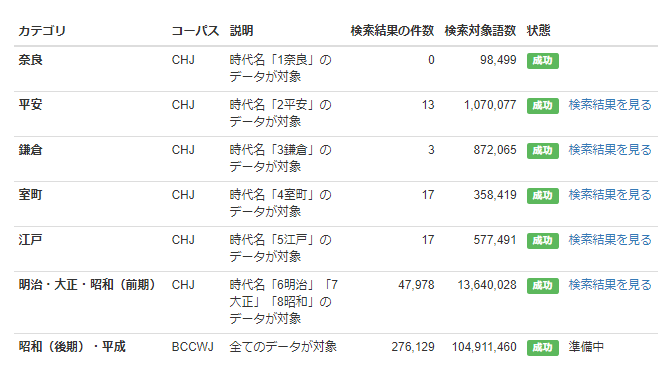
調整頻度とは?
最後にここで、グラフ表示に使われている「調整頻度」について解説を行います。
サイズ(検索対象語数)の大きく異なる2つコーパス間で単語の出現頻度を比較しようとしたとき、
極端な例、もし一方のコーパスのサイズが1万語規模(コーパスS)であったとして、もう片方が100億語の規模(コーパスXL)だとします。
そして、ある単語wのコーパスSでの出現回数が10、コーパスXLでは1万だったとします。
このとき、10と1万という数をそのまま比較しても意味がありません。
単語wの現れたコーパスのサイズ(分母)がまったく違うので、その大きさに合わせた頻度の「調整」が必要になります。
この際、各コーパスサイズに合わせて修正した単語wの頻度が「調整頻度」です。
一番単純な方法は単語wの出現回数を各コーパスの総語数で割って相対頻度に直すことですが、
コーパスの分野でよく用いられるのが、PMW(Per Million Words)です。
KOTONOHAでも調整頻度としてPMWを採用しています。
PMWでは、単語wの100万語当たりの出現頻度を計算します。
つまり、分母となるコーパスサイズが100万語となるよう、分子分母の比率を保ったまま相対頻度の分母(コーパスの総語数)を100万語に調整し、
その分子(調整後の単語wの出現回数)だけを取り出します。
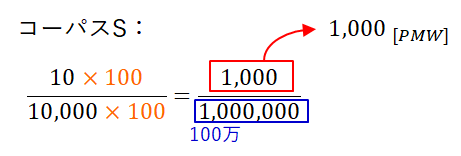
コーパスSは1万語規模なので、分母に100をかければ100万語になります。
よって、コーパスSで10回現れた単語wのPMWは1000です。
対して、コーパスXLは100億語規模なので、分母を1万で割れば100万語になります。よって、コーパスXLで1万回現れた単語wのPMWは1です。
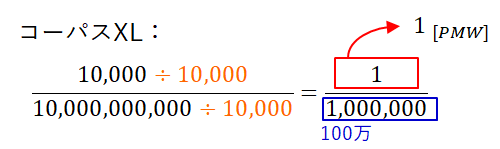
このようにPMWで比較すると、単語wはコーパスSでコーパスXLよりも多く出現していることになります。
ただし、1万語中にたった10回しか現れなかった単語の頻度をそのまま信用してしまってもいいのでしょうか?
10回という出現回数はあまりに少なく、もしかすると偶然で、もしかするとコーパスのサンプリング次第では0回であった可能性も捨てきれません。
そのため調整頻度はあくまで目安として、コーパスを分析していく際にはもともとのコーパスサイズや出現頻度、
そしてその出現事例を詳しくみていく必要があるのです。
